[AINews] Qwen 1.5 Released • ButtondownTwitterTwitter
Chapters
Discord Summaries
Perplexity AI Discord Summary
Discord Summaries
TheBloke Coding and Nous Research AI Highlights
Eleuther Research Discussion
Questions and Discussions in Mistral Channel
Mistral Deployment & Fine-Tuning
LangChain AI General
Performance Analysis and Object Misidentification
Connection and Innovation in Discord Communities
Discord Summaries
The section discussed various Discord summaries related to AI topics. The topics included the release of Qwen 1.5 and its performance, discussions on models like Sparsetral, debates on fine-tuning vs merging datasets, and knowledge sharing within the AI community. Other topics covered kanji generation challenges, AI-related scams, VR prototypes by Meta, and discussions on AI model performance, licensing changes, and interpretability. The section also touched on scalability in AI research, model evaluation methodologies, vector semantics, LM pre-training initiatives, and conversational AI fine-tuning techniques across different Discord communities.
Perplexity AI Discord Summary
- Pro Payment Problems: Users encountering issues with the Pro upgrade payments, facing unresponsive customer support, and recommendations for seeking assistance.
- AI Ethics in Education Debated: Discussion on the importance of AI offering culturally sensitive support in educational settings.
- Mismatched AI Research Responses: Experiences highlighting the limitations of AI in meeting research needs.
Discord Summaries
DiscoResearch Discord Summary
- A Danish language model utilizing the dare_ties merge method achieved 2nd place on the Mainland Scandinavian NLG leaderboard.
- LeoLM models can be merged without GPUs, offering alternatives like Google Colab for model merging.
- A 7b parameter German model named Wiedervereinigung-7b-dpo-laser was introduced, combining top German models.
- Conversation highlights improving use-cases like chat functions after merging models, prioritizing beyond achieving high scores.
- Jina AI released new code embeddings supporting English and 30 programming languages with a sequence length of 8192.
Alignment Lab AI Discord Summary
- An engineer faced unexpected training loss curve with LLama2 due to a high learning rate, recommended alternative configurations with Axolotl.
- Discussion on node infrastructure led by anastasia_ankr, fostering community engagement and pending communications awareness.
- Community contributions keeping the atmosphere friendly and active, celebrating collaborative spirit.
Datasette - LLM (@SimonW) Discord Summary
- Audacity integrated Intel's AI tools for powerful local features like noise suppression, transcription, and music separation, providing competition for subscription services.
- LLM integration sought advice for handling PDFs and web searches, questioning transferring chat histories across different models.
- Integration potential of LLM with Hugging Face's transformers highlighted for advanced Text-to-SQL capabilities.
LLM Perf Enthusiasts AI Discord Summary
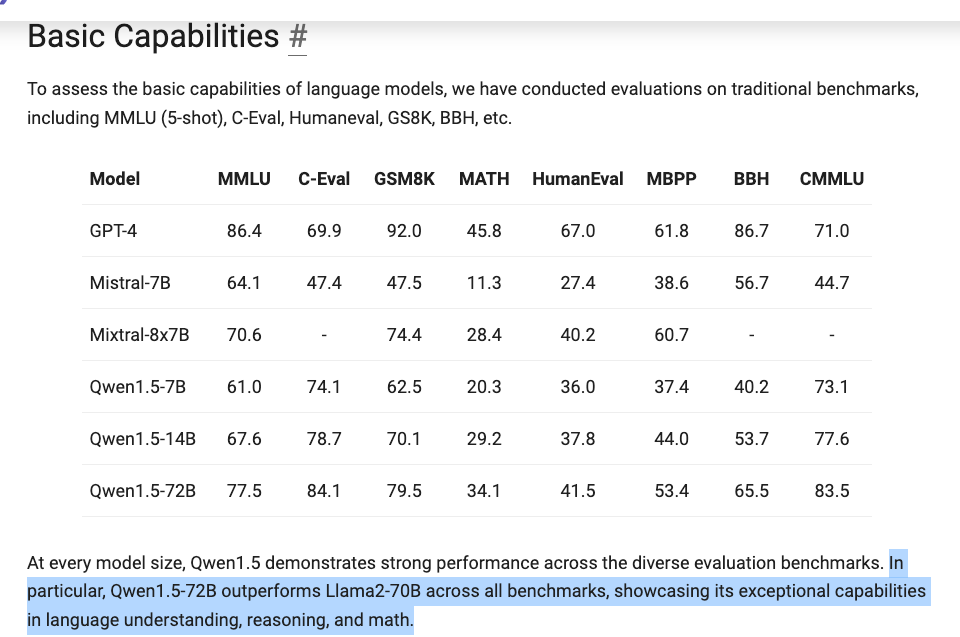
- Qwen1.5 introduction and open-sourcing offering models across six sizes, showcasing performance on par with larger models as a breakthrough in efficiency.
- Community impressed by Qwen1.5 efficiency, signaling a new wave in model optimization.
TheBloke Coding and Nous Research AI Highlights
TheBloke Coding:
- Users in the coding section discussed various topics such as creating character memory with ChromeDB, seeking shared links for neThing.xyz project, and sharing links to Code-13B and Code-33B Large Language Models trained on Python datasets.
Nous Research AI Off-Topic:
- Discussions included frustrations with training a model on Japanese Kanji generation, considering the dataset IDS repository for character structure understanding, speculating on AI breeding game theory, and raising awareness about AI-related scams on Facebook.
Nous Research AI Interesting Links:
- Users introduced new models such as bagel-7b-v0.4, DeepSeek-Math-7b-instruct, and Sparsetral-16x7B-v2, highlighting their features and potential use cases.
Nous Research AI General:
- Topics ranged from IPO performance discussions, quantization sensitivity, upcoming releases anticipation, model-similarity tool introduction, to concerns over Qwen 1.5 release quality and model capabilities.
Nous Research AI Ask-About-LLMs:
- Users shared insights on fusing QKV matrices for performance, using langchain for conversation history with LLMs, discussed licensing questions on Hermes 2.5 dataset, and sought advice on configuring special tokens for OpenHermes models.
Eleuther General:
- Highlights included discussions on creating foundational models, costs associated with it, Qwen1.5 model release details, interpretability of large language models, and concerns over AGI claims and model capabilities.
Eleuther Research Discussion
This section of the Eleuther Discord channel features a discussion on various topics related to research and advancements in the field of machine learning and AI. Some of the key points include clarifications on multi-task loss handling, exploring hypernetworks for LoRA weights, discussing CNN training methodology, debating the use of Polyquant activation function, and more. The members engage in debates, share links to relevant tweets, blog posts, and GitHub repositories, and exchange ideas on optimizing models, studies on scaling laws, and interpreting vectors in deep learning. The section also showcases a diversity of viewpoints on topics like conditional distributions, handling scaling studies, and the potential of using alternative activation functions in neural networks.
Questions and Discussions in Mistral Channel
The Mistral channel on Discord saw various conversations unfold. Users expressed concerns about LangChain's sustainability, searched for Mac-compatible model interpreters, and discussed the deterministic nature of Mistral 8x7B. Additionally, philosophical perspectives on AI were explored, and the secrecy around synthetic data generation methods was highlighted as a vital income source.
Mistral Deployment & Fine-Tuning
This section discusses various messages related to Mistral deployment and fine-tuning. Users inquire about prompt enhancement queries, PHP to JSON schema for better prompts, and padding dilemmas in fine-tuning. Additionally, there is a highlight on a Discord chatbot achieving a milestone with multiple LLM support and features. The section also covers discussions on Mistral models terminating with emojis in responses, showcasing the successes and challenges faced in utilizing Mistral API models.
LangChain AI General
In the LangChain AI general channel, various discussions were held related to different topics. The conversations included user recommendations on cloud GPU nodes, the introduction of a new embedding model called BGE-M3, instructions on using OpenAIEmbedder for embeddings, insights on data preprocessing comparison between Llama Index and LangChain, and a query about translating HTML with LangChain while preserving styles. Additionally, users shared links to resources like the new embedding model's GitHub repository and paper, LangChain's JavaScript and Python documentation, and a Stack Overflow question for community response on data preprocessing differences.
Performance Analysis and Object Misidentification
During performance tests, it was noted that OWLSAM did not capture everything correctly according to <em>“some tests”</em>. Additionally, OWLSAM was reported to misidentify objects, capturing incorrect objects during the tests. This indicates a potential issue with the model's object detection accuracy.
Connection and Innovation in Discord Communities
Discord offers a platform for communication, collaboration, and innovation within various communities. In a discussion within the DiscoResearch channel, members shared insights on model merging techniques, the effectiveness of laser treatment for language models, and the unveiling of high-performing German language models. The chat also explored Jina AI's new code embeddings supporting neural search applications. In the Alignment Lab AI channel, challenges related to training loss curves, business development networking, and the encouragement of idea exchange were discussed. The Datasette channel highlighted Audacity's integration of free AI tools from Intel, enhancing user capabilities for audio editing. Lastly, the LLM Perf Enthusiasts AI channel introduced the Qwen1.5 model, boasting efficiency improvements and performance comparable to larger models like Llama 7B.
FAQ
Q: What are some of the AI topics discussed in the given essai?
A: Topics discussed include the release of Qwen 1.5, Sparsetral models, debates on fine-tuning vs merging datasets, AI model performance, licensing changes, interpretability, kanji generation challenges, AI scams, VR prototypes by Meta, scalability in AI research, model evaluation methodologies, vector semantics, LM pre-training initiatives, and conversational AI techniques.
Q: What are some key points highlighted in the DiscoResearch Discord summary?
A: The DiscoResearch Discord summary highlighted a Danish language model achieving 2nd place in the Mainland Scandinavian NLG leaderboard, merging LeoLM models without GPUs, introduction of a 7b parameter German model Wiedervereinigung-7b-dpo-laser, improving use-cases post model merging, and new code embeddings by Jina AI supporting English and programming languages.
Q: What topics were discussed in the Alignment Lab AI Discord summary?
A: The Alignment Lab AI Discord summary discussed unexpected training loss curves with LLama2, node infrastructure discussions led by anastasia_ankr, fostering community engagement, and community contributions aimed at maintaining a friendly and active atmosphere.
Q: Which local feature enhancements were highlighted in the Datasette - LLM Discord summary?
A: The Datasette - LLM Discord summary highlighted Audacity's integration of Intel's AI tools for noise suppression, transcription, and music separation, providing competition for subscription services.
Q: What were the key points discussed in the LLM Perf Enthusiasts AI Discord summary?
A: The LLM Perf Enthusiasts AI Discord summary focused on the introduction and open-sourcing of Qwen1.5 models across six sizes, showcasing breakthrough efficiency and performance on par with larger models.
Q: What were some of the topics discussed in TheBloke Coding section?
A: The topics discussed in TheBloke Coding section included creating character memory with ChromeDB, shared links for neThing.xyz project, and links to Code-13B and Code-33B Large Language Models trained on Python datasets.
Q: What AI-related topics were explored in the Nous Research AI Off-Topic section?
A: The Nous Research AI Off-Topic section explored discussions on training models for Japanese Kanji generation, utilization of the IDS repository for character structure understanding, speculation on AI breeding game theory, and raising awareness about AI-related scams on Facebook.
Q: What interesting links and models were introduced in the Nous Research AI Interesting Links section?
A: The Nous Research AI Interesting Links section introduced new models like bagel-7b-v0.4, DeepSeek-Math-7b-instruct, and Sparsetral-16x7B-v2, highlighting their features and potential use cases.
Q: What were some general topics discussed in the Nous Research AI General section?
A: Topics in the Nous Research AI General section included IPO performance discussions, quantization sensitivity, upcoming releases anticipation, model-similarity tool introduction, concerns over Qwen 1.5 release quality, and model capabilities.
Q: What insights were shared in the Nous Research AI Ask-About-LLMs section?
A: Users shared insights on fusing QKV matrices for performance, using langchain for conversation history with LLMs, licensing questions on Hermes 2.5 dataset, and configuring special tokens for OpenHermes models.
Q: What topics were highlighted in The Eleuther General section on Discord?
A: The Eleuther General section discussed creating foundational models, costs associated with it, Qwen1.5 model release details, interpretability of large language models, and concerns over AGI claims and model capabilities.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!