[AINews] Jamba: Mixture of Architectures dethrones Mixtral • ButtondownTwitterTwitter
Chapters
AI Reddit and Twitter Recap
Eleuther Discord
Dynamic Shapes and CUDA Discussions
Discord Channel Discussions in LM Studio
LM Studio 0.2.18 ROCm Beta Release
Context Matters in LLM Behavior
AI Discussions Highlights
Discussions on Various AI Models and Licensing Terms
Exploring Different Conversations in Eleuther Channels
OpenAI and HuggingFace Discussions
Repository Updates and Community Engagements
Collaboration and Learning around CUDA in OpenCV
Miscellaneous Discussions on CUDA, RAG Techniques, and LLMs
Models
LangChain Pinecone Integration and Other Discussions
Exploring Translation Tools and Techniques
AI Reddit and Twitter Recap
This section provides a recap of discussions and developments in the AI community on Reddit and Twitter. It covers various topics such as Large Language Models, Stable Diffusion & Image Generation, AI Assistants & Agents, AI Hardware & Performance, and Memes & Humor. Highlights include the introduction of models like DBRX, discussions on attention models, and debates on AI ethics. The summaries offer insights into the ongoing conversations and advancements within the AI landscape on popular social media platforms.
Eleuther Discord
This section of the web page discusses various developments and discussions on the Eleuther Discord server related to the introduction of DBRX, token efficiency debates, layer-pruning impact on LLMs, innovation in model fusion with Jamba, and more. It covers topics like the conscious evaluations demonstrated by Claude 3, DBRX's impressive performance, and ongoing debates on the efficiency of transformer architectures. Additionally, the section touches on fine-tuning strategies, cosine similarity discussions, and efforts to troubleshoot technical challenges like screen sharing issues on Discord.
Dynamic Shapes and CUDA Discussions
OpenRouter (Alex Atallah) Discord
- Users faced various issues and discussions related to Gemini models, Gemini Pro 1.5, and Ethereum Payment shifts. The evolving landscape of cryptocurrency payments in AI was emphasized.
CUDA MODE Discord
- Community members analyzed dynamic CUDA support in OpenCV's DNN module, shared a survey on CUDA-enabled hardware, and discussed Triton tutorials and troubleshooting steps. Enthusiasts also delved into CUDA resources, Torch troubleshooting, and attention mechanisms like Ring Attention.
LlamaIndex Discord
- Discussions revolved around RAG optimization, LLMxLaw Hackathon, managing messy data with Llamaparse, and pipeline optimization. The community also explored the resources for CUDA skills and sought experts for CUDA-related opportunities.
OpenAccess AI Collective (axolotl) Discord
- Topics included Databricks' DBRX models, Jamba by AI21 Labs, AI model performance benchmarks, and resources for fine-tuning open source models. Discussions also touched on the impact of NVIDIA in MLPerf, SYCL as an alternative to CUDA, and OpenCL and Vulkan in accelerating hardware.
LAION Discord
- Conversations encompassed AI self-awareness, voice acting in light of AI advancement, AI model benchmarks, AI model pruning, Devika project in software engineering, and PDF to JSON conversion tutorials.
Tinygrad (George Hotz) Discord
- Debates and insights were shared on tinygrad's performance improvements, MLPerf Inference results, SYCL adoption, API discussions, and views on OpenCL and Vulkan. Community members also explored the potential of view merging in tinygrad.
LangChain AI Discord
- Engagements delved into JavaScript chatbots, deploying RAG apps with LangChain, LangSmith's AI tracing, and tutorials on PDF to JSON conversion. The community also discussed OpenGPTs project and document retrieval strategies.
Interconnects (Nathan Lambert) Discord
- Topics covered DBRX and Jamba models in the LLM scene, Mosaic's Law, experiments with architectural evolution, and discussions on language model spectrum and project stewardship transitions in the AI community.
DiscoResearch Discord
- Conversations included Databricks' DBRX Instruct model, its unique features, and bug fixes, as well as hands-on experiences with DBRX Instruct and Mixtral's multilingual translation API.
Discord Channel Discussions in LM Studio
In the LM Studio section of the Discord channels, users engage in discussions related to various topics such as model IDs, platform adaptability, system prompts, storage space concerns, GPU compatibility, and more. Members explore the merging of models, the release of DBRX Instruct, and LM Studio features like the API, system prompts, and performance. The Discord also tackles hardware discussions including GPU choices like NVIDIA models, monitor preferences, PSU requirements, and troubleshooting scenarios. Additionally, the community shares feedback on the usability of LM Studio, bug fixes in version 0.2.18, documentation updates, and new configurations available for download.
LM Studio 0.2.18 ROCm Beta Release
The recent LM Studio 0.2.18 ROCm Beta release includes bug fixes and stability improvements, addressing issues such as image duplication in chat and GPU offload problems. Users are encouraged to report bugs and can download the new release. Additionally, there are discussions on loading errors, low GPU utilization, mixed feedback on performance, and a bug related to local inference ejections found in this version. Members share their experiences and feedback on various aspects of the release.
Context Matters in LLM Behavior
A member discussed challenges with paragraph splitting for Large Language Models (LLMs), noting that models like Mistral struggle with longer context. Tokenization issues and evaluating sentence splits were highlighted, mentioning the difficulty of prompting LLMs, especially in recalling specific paragraphs like the 'abstract'. The conversation also included sharing code for evaluating LLM tasks, focusing on code availability for checking exact matches post-sentence splitting.
AI Discussions Highlights
This section delves into various discussions on AI-related topics from different Discord channels. One conversation analyzed the performance of a large model with 16x12B and 4 experts per token compared to Mixtral-Instruct, leading to a discourse on model expectations and benchmarks. Another discussion focused on the challenges in Retrieval Augmented Generation (RAG) and the importance of well-defined scenarios in Chain of Thought (CoT) for retrieval or answering tasks. There was also an in-depth exploration of _philschmid's approach to Retrieval Augmented Thoughts (RAT), highlighting the potential for high-quality code generation and creative writing. Members shared diverse objectives and requirements for building a model that can utilize external context effectively. The section also covers debates on input methods like leveraging XML tags, and structured formats for organizing prompts and responses. Lastly, it mentions Stability.ai's discussions on the anticipated release of Stable Diffusion 3 (SD3), memory requirements for language models like Mixtral, and techniques to improve image prompts for models like SDXL.
Discussions on Various AI Models and Licensing Terms
The section discusses the unveiling of Databricks' DBRX-Instruct AI model, which is trained on 132 billion parameters and trained using NVIDIA H100 GPUs. It also delves into community discussions surrounding DBRX's licensing terms and the skepticism expressed by TechCrunch regarding its competitiveness with OpenAI's GPT series. Additionally, there is mention of Hume AI's emotionally aware chatbot impressing users with its emotion analysis feature.
Exploring Different Conversations in Eleuther Channels
- Layer-Pruning Strategy Explored: Research on layer-pruning strategies for LLMs shows minimal performance degradation on question-answering benchmarks even with up to half the layers removed.
- SYCL Outperforms CUDA: An SYCL implementation of MLPs optimized for Intel's Data Center GPU Max 1550 outperforms an equivalent CUDA implementation.
- DBRX LLM Introduced by Databricks: DBRX model designed by Databricks sets new performance benchmarks and offers a fine-grained MoE architecture.
- Efficient Fine-Tuning with LISA: LISA technique for fine-tuning large language models with efficiency gains and performance improvements over LoRA.
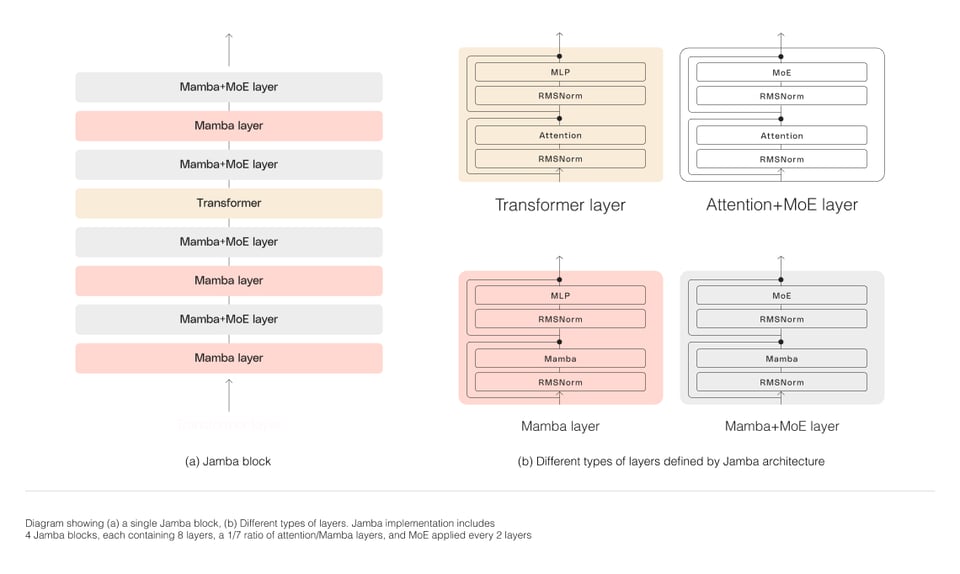
- AI21 Releases Transformer-SSM Fusion: AI21 unveils a new model combining Structured State Space model architecture with Transformer technology for improved performance and capability.
OpenAI and HuggingFace Discussions
OpenAI API Discussions
- A member provided a prompt rewrite focusing on instructing the model on what to do instead of what not to do when translating English text containing HTML.
- Discussions on JSON schema issues, ensuring full code output from ChatGPT, commenting conundrums in code, crafting visual descriptions with GPT, and prompt crafting for translation consistency were highlighted.
HuggingFace General
- Discussions about YOLOv1's image handling, limitations of RLHF on model alignment, model selection for GPU inference on AWS SageMaker, running large language models locally versus on the cloud, and accessing GPU benchmarks and framework comparisons were detailed.
HuggingFace Today I'm Learning
- Topics covered include DeepSpeed Zero-3 parallelization, Groq's AI approach, and enlightening reads on cell types and gene markers.
Hugging Face Cool Finds
- Topics encompass efficient embedding quantization for search, the success of HuggingFace's Visual Studio Code Extension, semantic search and precision savings, and sharing experiences running LLMs locally.
HuggingFace I Made This
- Highlights include a new protein embedding model, a diffusion model guidance technique, and datasets related to hypergraph representation learning.
HuggingFace Reading Group
- Exploration of customizing text-driven images, prompts for personalized images, and challenges with textual inversion were discussed.
HuggingFace Core Announcements
- MPS support added to training scripts was a key highlight.
HuggingFace Computer Vision
- Discussion points involved harnessing stitched images for training, training models for technical drawing image summarization, frustrations with DETR fine-tuning, and assisting users with zero-shot image classifier tune-ups.
HuggingFace NLP
- Topics included NLP roadmaps for 2024, improving session-based recommendation systems, loading errors with the Bart CNN summarization model, setup inquiries for exploring RAG, and issues with LLM's generative behavior.
HuggingFace Diffusion Discussions
- Discussions on stable diffusion image variation, alternative image generation methods with DreamBooth, community contributions to diffusers, and encouraging community discussions were detailed.
Repository Updates and Community Engagements
The section discusses updates to repositories and documentation enhancements, along with community interactions. Users inquire about experiences with labmlai diffusion repository and seek assistance for EU product distribution. Discussions cover exploring sub-prompts from Claude for agentic behavior, using OpenInterpreter from UIs or IDEs, running OpenInterpreter in offline mode, and community engagement in software innovation. Various links mentioned in the discussions point to GitHub resources and guides for local LLMs. The section also touches on topics related to Python interop in Mojo, GitHub contribution privacy concerns, and Rust resources for deep dive. Encouragement and anticipation for future LLM performance optimization, particularly local LLM models, are expressed. The community also shows interest in Mojo's general capabilities and the potential rewrite of existing tooling to maximize benefits.
Collaboration and Learning around CUDA in OpenCV
Seeking Collaboration for Dynamic CUDA in OpenCV: Sagar Gupta, a CS undergrad, is inviting collaboration on implementing dynamic CUDA support in OpenCV's DNN module. A short survey was provided to gather experiences and expectations regarding dynamic CUDA support with the link: OpenCV DNN CUDA Interface Survey.
Catching up with CUDA Online Resources: Pessimistic_neko suggested a book on CUDA for learning purposes and provided an Amazon link, but the content showed a CAPTCHA challenge instead of the book information.
Comprehensive CUDA Course Material: Andreas Koepf recommended visiting a GitHub repository that lists CUDA resources, including courses: CUDA Course Material on GitHub.
Classic CUDA Course for Beginners: Cudawarped shared a link to a classic Udacity course on parallel programming for beginners interested in CUDA, with a playlist available on YouTube: Intro to Parallel Programming Course on YouTube.
Miscellaneous Discussions on CUDA, RAG Techniques, and LLMs
This chunk includes various discussions on topics related to CUDA, Ring Attention Mechanisms, and Large Language Models (LLMs). In the CUDA section, troubleshooting tips and discussions on CUDA setup for Windows using PyTorch and WSL are shared. The Ring Attention segment delves into the specifics of Ring Attention versus Blockwise and Flash Attention, along with insights on training large language models with limited resources. Additionally, there are conversations about Triton kernels, debugging techniques, and tips for optimizing memory usage in RAG pipelines. The chunk also covers the launch of the Centre for GenAIOps, inquiries about LLM training resources, and a guide on building RAG systems with LlamaIndex and MongoDB. Lastly, the chunk discusses the unveiling of DBRX LLMs by Databricks, technical issues faced by Axolotl users, the introduction of Jamba architecture by AI21 Labs, and community reactions to new LLM releases, demonstrating a mix of excitement and skepticism.
Models
The section discusses various insights shared by the collective on LLM training, highlighting the importance of chronological order in data batching. However, there is a lack of consensus or readily available resources on the best practices for training LLMs from scratch. Key points include fixing a batch size bug in training, the introduction of DBRX Base and Instruct models, challenges with loading gigantic models, the introduction of the LISA method, and the discussion on using bf16 for training and optimization. Additionally, topics such as layer pruning for efficient LLMs, B-LoRA for style-content separation in images, open-source tools for VLM image captioning, and the introduction of the mini-Gemini model are covered in this section.
LangChain Pinecone Integration and Other Discussions
The section discusses various topics related to LangChain, including issues with the Pinecone integration documentation, custom logging and tracing with LangSmith, storing vectorized document data in a PostgreSQL database, and an inquiry about Pythia, an AI hallucination detection app. Additionally, the section includes shared YouTube tutorials on PDF to JSON conversion using LangChain's Output Parsers and GPT, the launch of GoatStack AI for personalized AI research summaries, and an experiment on hacking OpenGPTs. The section also highlights the introduction of DBRX, a large language model with 132 billion parameters, and the release of Jamba by AI21, a model blending Mamba and Transformers architectures with a 256K context window.
Exploring Translation Tools and Techniques
In this section, various tools and techniques for translation are discussed. Mixtral's API offers free access with rate limits, Occi 7B model provides high-quality translations, a member plans to filter out incorrect samples for better quality, and there is interest in comparing translations across different models. Additionally, a GitHub script for translations is shared. Another segment introduces DBRX, a new LLM outperforming GPT-3.5. Members seek simplified explanations and discuss the programming capabilities of DBRX. A link is provided for more information on DBRX. Lastly, LLM enthusiasts are invited to a coffee gathering event, with discussions on co-working spaces for the LLM community. A link for RSVP to the event is also included.
FAQ
Q: What is DBRX and what are its key features?
A: DBRX is a large language model introduced by Databricks with 132 billion parameters. It offers a fine-grained MoE (Mixture of Experts) architecture, setting new performance benchmarks in the AI landscape.
Q: What is the Layer-Pruning strategy in the context of Large Language Models (LLMs)?
A: Research on layer-pruning strategies for LLMs shows minimal performance degradation on question-answering benchmarks even with up to half the layers removed.
Q: What is the difference between SYCL and CUDA in terms of performance?
A: An SYCL implementation of MLPs optimized for Intel's Data Center GPU Max 1550 outperforms an equivalent CUDA implementation
Q: What is the LISA technique and how does it improve fine-tuning of large language models?
A: LISA is a technique for fine-tuning large language models that offers efficiency gains and performance improvements over LoRA.
Q: What is the Transformer-SSM Fusion model released by AI21?
A: AI21 released a new model combining Structured State Space model architecture with Transformer technology for improved performance and capability.
Q: What are the main topics discussed in the HuggingFace Today I'm Learning channel?
A: The HuggingFace Today I'm Learning channel covers topics such as DeepSpeed Zero-3 parallelization, Groq's AI approach, and insights on cell types and gene markers.
Q: What are some key points shared in discussions related to CUDA in the Discord channels?
A: Discussions on CUDA involve troubleshooting tips, CUDA setup for Windows using PyTorch and WSL, insights on Ring Attention versus Blockwise and Flash Attention, and optimizing memory usage in RAG pipelines.
Q: What are some highlighted discussions in the LangChain AI Discord channel?
A: Discussions in the LangChain AI channel include issues with Pinecone integration documentation, custom logging with LangSmith, tutorials on PDF to JSON conversion, the launch of GoatStack AI, and the introduction of DBRX and Jamba models.
Q: What are some insights shared in the section related to translation tools and techniques?
A: Insights include Mixtral's API offering free access with rate limits, the high-quality translations provided by Occi 7B model, discussions on DBRX's programming capabilities, and an invitation to a coffee gathering event for LLM enthusiasts.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!